引言
“AI"可能是这个时代被使用最多、也被误解最多的一个词。
一个创业者说"我们的产品用了 AI”,他可能只是接了一个 ChatGPT 的 API。一个投资人说"AI 赛道",他可能指的是从芯片到应用的整条产业链。一个家长说"AI 会不会取代我孩子的工作",他心里想的可能是一个无所不能的机器人。而一个研究者说"AI 还远远不够",他在谈论的是一个我们甚至无法定义的目标——通用智能。
同一个词,在不同语境下,指向完全不同的东西。 概念的混淆带来判断的失误——有人高估它,有人恐惧它,有人在错误的层面上讨论它。
这篇文章想做一件事:画一张地图。
把 AI、机器学习、神经网络、深度学习、Transformer、LLM 这些纠缠在一起的概念各归其位。更重要的是,我想讲清楚一件大多数人没意识到的事:当下这波 AI 浪潮的底层,不是某个具体的产品或模型,而是一次认知范式的更换——它和传统软件的区别,不是程度上的,而是本质上的。
一、AI 家族的层级关系
AI 领域的这些概念不是并列的,而是层层嵌套的——每一层都完整地包含在外面一层里。
每一层都完整地包含在外面一层里——所有 LLM 都是深度学习,所有深度学习都是机器学习,所有机器学习都是 AI。但反过来不成立:很多 AI 不是机器学习(比如 1980 年代的专家系统),很多机器学习不是深度学习(比如决策树)。
这张图解决了一大半的术语混乱。接下来我们进入最重要的那一层。
二、机器学习:一次被低估的范式革命
2.1 一切始于一个反转
AI 研究经历了几十年的探索,最终汇聚到一条主线上。这条主线的名字叫机器学习。
理解机器学习,最好的方式不是定义它,而是把它和你已经熟悉的东西做对比。
Keras 框架的创建者 François Chollet 画过一张被引用了无数次的图,它用最少的笔墨捕捉了这次范式转变的本质:
程序
学习
(模型)
传统编程: 人类写规则 + 数据 → 答案。 机器学习: 数据 + 答案 → 机器自己找出规则。
箭头的方向反了。 这就是全部。
但这个反转的意义是深远的。用一个例子来感受。
2.2 一个例子:预测上海的房价
假设你有一批上海二手房成交数据——面积和成交价。你想预测一套新房子能卖多少钱。
传统做法: 你是资深中介,凭经验写规则——
if 陆家嘴 and 面积 > 100: 价格 = 面积 × 12万
elif 外环外: 价格 = 面积 × 3万
elif 老静安 and 学区房: 价格 = 面积 × 15万
...
这些规则能用,但永远不够精确。同一个小区的不同楼层、朝向、楼龄、装修都会影响价格,排列组合有几千种。你写不完,也调不准。
更要命的是:市场在变。去年的规则今年就不准了,你得不断回来改代码。
机器学习做法完全不同。 你不写任何规则。你把所有历史成交数据(面积、楼层、朝向……和真实成交价)一股脑丢给机器,说一句话:
“你自己去找面积和价格之间的关系。”
机器怎么做?三步循环:
第一步:随机猜。 机器先随便猜一组参数,比如 价格 = 0.5 × 面积 + 100。这条线画出来跟真实数据点差得很远。
第二步:量化"差多远"。 用一个叫 Loss(损失函数) 的数字来衡量预测值和真实值的差距。Loss 越大,错得越离谱。
第三步:往更好的方向调一小步。 计算 Loss 对每个参数的导数(梯度),朝着让 Loss 变小的方向微调参数。这就是梯度下降——想象你蒙着眼站在山上,用脚探路,每次朝下坡方向迈一小步。
然后重复。猜 → 量化差距 → 调整。几千次之后,那条线就贴合了数据。
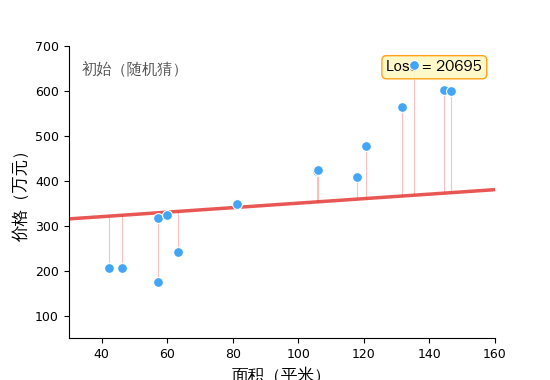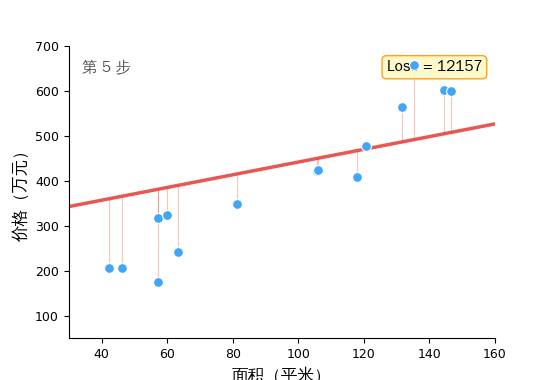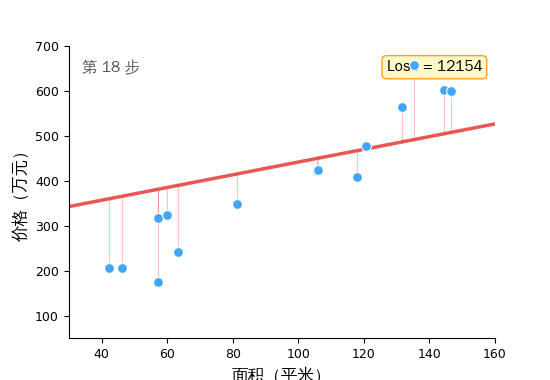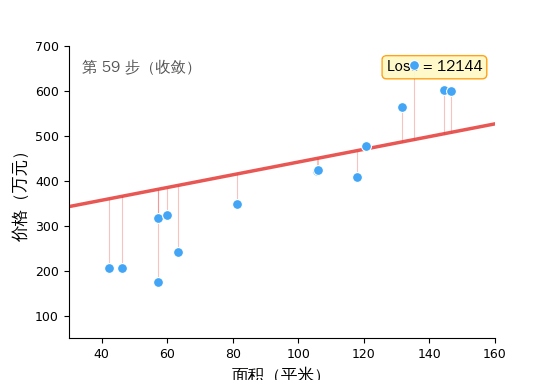
这个循环——前向传播、计算 Loss、梯度下降——是所有机器学习的训练核心。 从 1990 年代的线性回归到 2024 年训练 GPT-4,底层都是它。
2.3 但等一下——人到底做了什么?
走到这里,你应该有一个疑惑:
“你说机器学习是’机器自己找规则’。但公式
y = wx + b不也是人定的吗?这跟传统编程有什么区别?”
好问题。这正是最容易混淆的地方。
让我们把分工彻底说清楚。机器学习中:
- 人类定框架——选什么结构的模型(一条直线?一个三层网络?一个 96 层 Transformer?),用什么损失函数,学习率设多大。这些叫超参数和架构设计。
- 机器填参数——在人定的框架内,通过梯度下降,从数据中找到最优的参数值。
一个类比:
传统编程像建筑师亲自砌每一块砖——墙放哪、门开多大,全部由人决定。
机器学习像建筑师只画了"三室两厅"的平面图,然后让一个自动化系统去试几千种具体布局方案,从中选出居住体验最好的那个。
图纸是人画的。房子是机器盖的。
这个区别在不同规模的模型中始终成立:
| 模型 | 人类定的框架 | 机器找的参数 |
|---|---|---|
| 线性回归 | y = wx + b | w, b(2 个数字) |
| 小型神经网络 | 3 层,每层 64 个神经元 | ~12,000 个权重 |
| GPT-3 | 96 层 Transformer | 1750 亿个权重 |
从 2 个参数到 1750 亿个——框架越复杂,机器能学到的模式越丰富。这就是大模型"涌现"能力的底层原因:不是算法变了,是框架给了机器更大的探索空间。
2.4 框架选错了会怎样?——过拟合
既然人类负责选框架,那选错了会发生什么?
还是房价例子。如果你用一条直线(2 个参数),可能太简单,学不到弯曲的趋势——这叫欠拟合。如果你用一条 15 次多项式曲线(16 个参数),模型有足够的灵活性穿过每一个数据点——在训练数据上完美,但面对新数据就一塌糊涂——这叫过拟合。
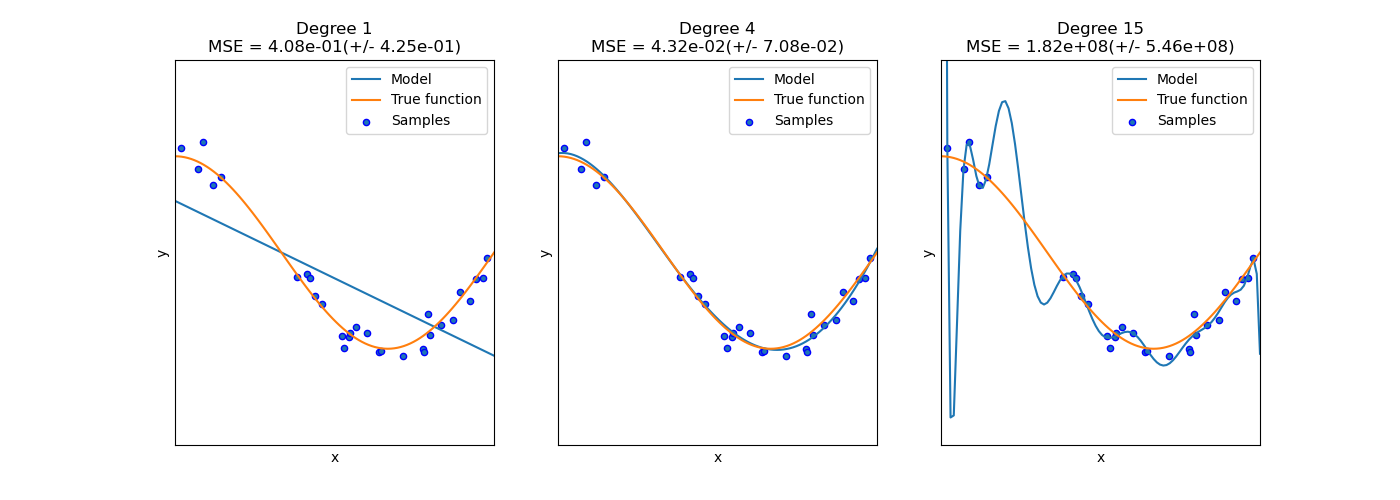
(来源:scikit-learn 官方文档,Underfitting vs. Overfitting)
过拟合的本质:机器把训练数据中的噪声也当成规律学进去了。 它"背"住了答案,而不是"理解"了规律。
这件事在 LLM 中同样存在——如果语言模型把训练数据背下来而不是学会语言的规律,它就会在训练数据之外的问题上"一本正经地胡说八道"。
所以机器学习工程师的核心技能之一,就是给机器选择恰当复杂度的框架。不能太简单,也不能太灵活。这个平衡点的选择,至今仍然更接近手艺而不是科学。
三、神经网络与深度学习:一段改名求生的历史
3.1 神经网络:简单到令人意外
一个人工神经元做的事只有一件:接收几个输入,加权求和,过一个激活函数。就这样。
但当你把成千上万个神经元连成网络,层层叠加——奇妙的事情发生了。网络开始能学会极其复杂的模式:从图片中认出猫、从语音中识别文字、从文本中预测下一个词。
神经网络本质上就是一种机器学习的框架——一种特别灵活的、层次化的函数结构。人定义"几层、每层多宽",机器通过梯度下降来填充所有权重。
3.2 四十年的寒冬
1969 年,AI 先驱 Marvin Minsky 用数学证明了单层神经网络连最简单的异或逻辑都学不会。这本书(《Perceptrons》)的杀伤力是毁灭性的——整个学术界得出结论:神经网络是死路一条。
经费被砍,论文被拒,研究者被嘲笑。从 1969 年到 2006 年,将近四十年,做神经网络研究的人在学术界被视为异端。NeurIPS 会议上投稿神经网络论文,评审意见常常就一句话:“This is just a neural network.”
Geoffrey Hinton 在加拿大多伦多大学,带着极少经费,一年又一年地发论文,一年又一年地被无视。他后来说:
“我们就像一小群人在沙漠中行走,所有人都说前面没有绿洲。”
3.3 “深度学习”——一个绕过偏见的名字
2006 年,Hinton 证明了深层网络可以被有效训练。但问题是:“Neural Network"这三个字已经臭了。 四十年的冷遇让这个词在学术界等同于"过时、已被证伪、不值得讨论”。
于是他和同行开始用一个新名字:Deep Learning。
同样的技术,换了个名字,绕过了四十年的偏见。 2012 年 AlexNet 用两块游戏显卡在图像识别比赛中碾压所有传统方法后,“深度学习"彻底爆发。
2018 年,Hinton、LeCun 和 Bengio 三人获得图灵奖。从异端到最高荣誉,他们等了三十年。
这段历史的完整故事,可以看 《AI 的 70 年》三部曲。
3.4 深度学习是一个家族
深度学习不是一种方法,而是一组不同的网络架构,各有擅长:
| 架构 | 擅长 | 代表 |
|---|---|---|
| CNN | 图像 | 人脸识别、自动驾驶 |
| RNN / LSTM | 序列 | 早期翻译、语音识别 |
| Transformer | 序列→一切 | GPT、Claude、DeepSeek |
| Diffusion | 图像生成 | Midjourney、Stable Diffusion |
“AI 能画画"是扩散模型,“AI 能聊天"是 Transformer——它们都是深度学习家族里的不同分支。
四、Transformer 与 LLM:最内圈的爆发
2017 年 Google 论文《Attention Is All You Need》提出 Transformer 架构。之前的 RNN 像逐字读书,读到第 100 个字时,第 1 个字已经记不清了。Transformer 像一眼扫完整页,然后直接计算任意两个词之间的关联。
它之所以能替代 RNN,是因为它天然适合 GPU 并行计算——恰好赶上了算力指数级增长的时代。
LLM(大语言模型) 就是用 Transformer 架构、在海量文本上训练出来的超大规模模型。它做的事本质上极其简单:预测下一个词。
但当框架足够大(1750 亿参数)、数据足够多(万亿 token)时,这个简单的任务涌现出了对话、推理、编程、创作等能力。
一个 LLM 从训练到变成你手里的 ChatGPT,要经过四个阶段:
预训练 指令微调 对话微调 技能扩展
"读遍天下书" "学会听指令" "学会聊天" "学会用工具"
↓ ↓ ↓ ↓
Base Model Instruct Model Chat Model AI 应用
每个阶段用的都是我们前面讲的东西:预训练用梯度下降,指令微调用监督学习,对话对齐用 RLHF(强化学习),技能扩展用 RAG 和 Agent。
机器学习不是 LLM 的"祖先”。它是 LLM 正在使用的每一项核心技术。
五、LLM 之上:AI 系统的完整拼图
LLM 是"大脑”,但光有大脑不够。一个完整的 AI 应用——比如你正在用的 ChatGPT 或 Claude——还需要记忆、工具和执行力:
理解所有输入,生成输出
| 组件 | 一句话 |
|---|---|
| RAG | 回答前先查资料——让 AI 能用最新知识 |
| Agent | 自主规划和执行的项目经理——不只是回答,还能办事 |
| MCP | AI 连接外部系统的统一接口——USB-C 式标准协议 |
| Skills | 把专家经验写成标准流程——让 AI 按章办事 |
所有让 AI 变聪明的技术,本质上都在做同一件事:给大脑喂更好的输入。
关于这些组件的详细拆解,会在后续文章中展开。
六、回到那张地图
现在我们可以回答引言中的问题了——当不同的人说"AI"时,他们到底在说什么:
| 语境 | 实际所指 |
|---|---|
| “我们产品用了 AI” | 最内圈:接了一个 LLM 的 API |
| “公司要上 AI” | AI 系统层:LLM + RAG + Agent 的集成方案 |
| “AI 替代程序员” | AI 系统层:Agent(LLM + 工具调用 + 自主循环) |
| “AI 能画画” | 深度学习层:扩散模型(不是 LLM) |
| “AI 还远远不够” | 最外圈的终极愿景:AGI(目前不存在) |
概念各归其位。但这篇文章真正想传递的,不是这张分类表。
真正重要的事
当下所有让你觉得"AI 爆发了"的东西——ChatGPT、Claude、Copilot、Midjourney——无一例外,都是机器学习的产物。它们共享同一个底层范式:
不是人类写规则让机器执行,而是人类提供数据让机器自己学。
这件事的意义比大多数人意识到的更深。
传统软件是确定性的——同样的输入永远产生同样的输出。你可以追踪每一步逻辑,定位每一个 bug,理解每一个决策。几十年的软件工程方法论——测试、调试、代码审查——都建立在这个确定性之上。
而机器学习产出的模型是概率性的——它给出的是"最可能的回答”,不是"确定正确的回答"。它的"知识"不在代码里,而在几千亿个浮点数组成的权重矩阵里。你无法逐行审查它的"逻辑",因为那些逻辑从未被人类显式写出——它们是从数据中涌现的。
| 传统软件 | AI / 机器学习 |
|---|---|
| 人类写逻辑 | 机器从数据中学 |
| 确定性输出 | 概率性输出 |
| 每一步可验证 | 整体可测试,内部不透明 |
| “知识"在代码里 | “知识"在权重矩阵里 |
| 修 bug = 改代码 | 修 bug = 换数据、调架构、重新训练 |
这不是技术升级。这是范式更换。
它意味着我们正在进入一个时代:越来越多影响你生活的决策——贷款审批、内容推荐、医疗诊断辅助——将由你无法审查其逻辑的系统做出。这些系统有效、强大、有时惊人地准确,但它们的工作方式与人类几千年来构建知识体系的方式根本不同。
理解这个范式转变——知道它的力量在哪里、边界在哪里、代价是什么——不是技术人员的专利。它是这个时代每一个人需要具备的基本素养。
这就是为什么我们要从头讲起。
延伸:动手体验与推荐阅读
理论看完了,想动手试一下?
| 资源 | 做什么 | 适合谁 |
|---|---|---|
| Google Teachable Machine | 用摄像头训练一个真实的图像分类器,5 分钟出结果 | 零基础,想亲手体验"训练模型” |
| TensorFlow Playground | 浏览器里调参,实时看神经网络学习分类边界 | 想直观感受"层数"和"神经元数量"的影响 |
| Jay Alammar 的可视化教程 | 交互式体验房价预测和梯度下降 | 想动手调权重、看 Loss 变化 |
| 3Blue1Brown 神经网络系列 | 用数学动画解释神经网络和梯度下降 | 想从数学层面建立直觉 |
本博客的相关深度文章:
- 《AI 的 70 年》三部曲 —— 从达特茅斯的梦想到 ChatGPT 的爆发
- 《AI 的数学语言》六篇系列 —— 从向量到梯度下降,零基础也能看懂
- 《Attention 机制零基础拆解》 —— 用加减乘除看懂注意力
- 《LLM 全流程可视化》 —— 从输入到输出的每一步
博客:AI-lab学习笔记 | 微信公众号:AI-lab学习笔记
