引言:一个让人失眠的问题
在准备一期介绍 Transformer 的视频时,我想从"发明者视角"来解释 QKV。
于是我问了自己一个问题:“苹果"这个词到底是什么?
想说清楚"苹果”,就得先说清楚"水果"。想说清楚"水果",得先说清楚"植物"。想说清楚"植物"……最终你会发现,要解释语言,你必须先拥有语言。
这是一个死循环。
更麻烦的是,“苹果"这个词关联的东西远不止"水果”——它同时连接着红色、酸甜、苹果树、iPhone、乔布斯、亚当与夏娃、《小苹果》广场舞、“You are the apple of my eye”……
我越想越觉得,如果连"一个词是什么"都说不清,又怎么可能解释 QKV 的设计?
但转念一想——也许正是因为语言本身就是这样运作的,QKV 才会被发明出来。
这篇文章从人类理解语言的方式出发,经过 40 年规则路线的失败、分布式假说的破局、机器世界的设计约束,最终抵达 QKV 的工程方案——然后我们会发现,硅基走过的路,和碳基惊人地相似。它不是一篇教你"QKV 怎么算"的技术文章——那部分我在 Attention 机制零基础拆解 中已经写过。这篇文章要回答的是:QKV 为什么会被发明出来?
第一章:语言的死循环——符号接地问题
字典的无限递归
试着用字典查"苹果":
苹果 → 一种水果
水果 → 植物的可食用果实
植物 → 能进行光合作用的生物
生物 → 具有生命特征的有机体
生命 → ……
每一个定义都依赖另一组词。你永远不可能仅仅通过词与词之间的互相解释,来触及那个真实的、可以咬一口的苹果。
这个问题在 1990 年被认知科学家 Stevan Harnad 正式提出,他称之为符号接地问题(Symbol Grounding Problem):
纯符号系统无法仅靠符号之间的互相解释来获得意义。
意义不能只从符号→符号的映射中产生。
换句话说:一本只有文字的字典,无论写得多详细,永远无法让一个从未见过苹果的人真正理解什么是苹果。
类比: 想象你在一个全是中文的房间里(没错,这就是著名的"中文房间"思想实验),你手里只有一本中中词典。你可以查到每个字的释义,但你永远无法跳出文字本身——因为释义也是文字。
这看起来是个无解的死胡同。
思考片刻: 如果你现在正在阅读这段文字并且"理解"了它——你是怎么做到的?你理解"苹果"时,脑子里浮现的是一个定义,还是一团关联的记忆、感受和场景?也许理解从来就不是一个"定义"的过程。
但面对这个死循环,人类并没有放弃。最直觉的尝试是——像学校教语言那样教机器。
第二章:人类的第一次尝试——像教孩子一样教机器
语言可以用规则描述……吗?
1957 年,语言学家 Noam Chomsky 提出了形式文法(Formal Grammar)——他相信,人类语言的核心是一组有限的规则,通过递归组合就能生成无限多的句子。
这个想法极其诱人。如果语言只是规则,那只要把规则告诉机器,机器就能"理解"语言。
早期的努力确实令人振奋。1971 年,MIT 的 Terry Winograd 构建了 SHRDLU 系统——一个只存在于"积木世界"里的语言理解程序。你可以用英语告诉它"把红色积木放到蓝色积木上面",它就能理解并执行。
人: Pick up a big red block.
SHRDLU: OK.
人: Find a block which is taller than the one you are holding.
SHRDLU: I can't find one.
人: Why did you pick up that block?
SHRDLU: To clear off the red block so I could put it on the blue block.
这看起来太像"理解"了!但问题是——SHRDLU 的世界只有几十种积木和几百条手工编写的规则。当研究者试图把它扩展到真实世界时,一切都崩塌了。
40 年的规则路线,三个致命问题
从 1950 年代到 1990 年代,几代语言学家和 AI 研究者投入了巨大的努力,试图用语法树、语义角色标注、格语法(Fillmore, 1968)、知识图谱等工具来形式化自然语言。
他们遇到了三个无法逾越的障碍:
IBM 语音识别团队的 Fred Jelinek 说过一句著名的话(大约 1988 年):
“Every time I fire a linguist, the performance of the speech recognizer goes up.”
每开除一个语言学家,语音识别的表现就进步一点。
这句话虽然刻薄,但指向了一个深刻的范式转换:语言也许不应该被描述为规则,而应该被理解为统计结构。
规则路线的核心问题是:它试图从上到下地定义语言。但如同符号接地问题所揭示的,定义本身就是语言的一部分——你在用语言来定义语言的规则,这又是一个死循环。
然后有人提出了一个完全不同的思路。
第三章:破局——“你可以通过同伴认识一个词”
绕过死循环的天才直觉
同样是 1957 年,英国语言学家 J.R. Firth 说了一句改变了整个自然语言处理方向的话:
“You shall know a word by the company it keeps.”
你可以通过一个词的同伴来认识它。
这句话的革命性在于:它不再试图定义"苹果是什么"。
它只观察"苹果"经常和谁一起出现:
意义不是预先定义的,意义是从大量上下文中涌现的。 这就是分布式假说(Distributional Hypothesis)。
有趣的是,哲学家 Ludwig Wittgenstein 在 1953 年的《哲学研究》中独立得出了类似结论。他的早期哲学(《逻辑哲学论》, 1921)曾相信语言可以精确地映射世界——每个词对应一个事物,就像规则路线所做的。但他的后期哲学完全推翻了自己:
“一个词的意义就是它在语言中的使用。” — Wittgenstein, Philosophical Investigations, §43
意义不在于指代,而在于使用的模式。一个词的含义不是从它指向的"对象"中获得的,而是从它参与的所有"语言游戏"中涌现的。
从 Chomsky 到 Firth,从早期 Wittgenstein 到后期 Wittgenstein,从规则到统计——这不仅是 AI 的范式转换,也是人类对语言本质认识的一次深刻转向。
它和规则路线的区别在于:规则路线试图定义语言,分布式假说试图观察语言。前者是自顶向下的演绎,后者是自底向上的归纳。
从哲学到工程:Word2Vec
2013 年,Google 的 Tomas Mikolov 团队将这个语言学直觉变成了工程现实——Word2Vec。
方法出奇地简单:让模型读海量文本,通过预测上下文来学习每个词的向量表示。当你把成千上万的词放进同一个高维空间,惊人的事情发生了:
国王 - 男 + 女 ≈ 女王
巴黎 - 法国 + 日本 ≈ 东京
“性别"竟然是高维空间中的一个方向。“首都关系"也是一个方向。 语义关系被自动编码为空间中的几何结构。
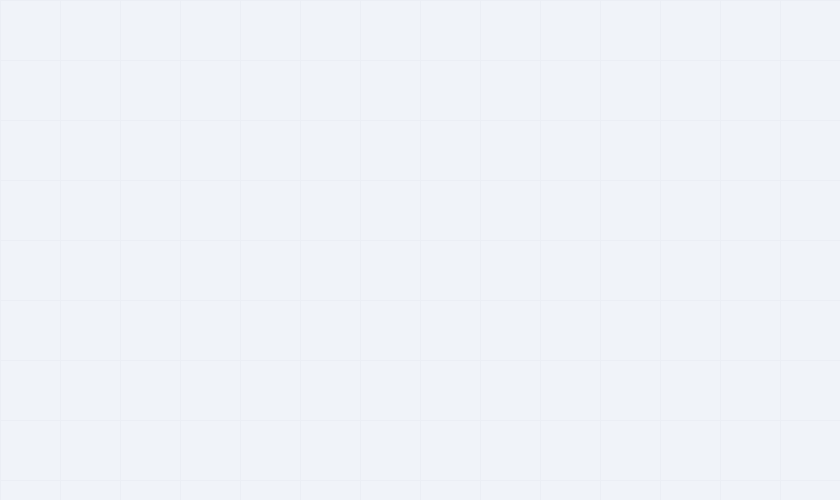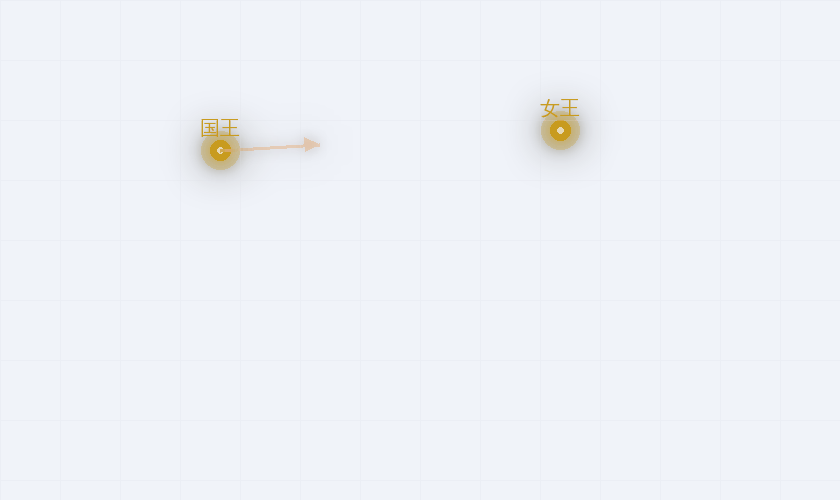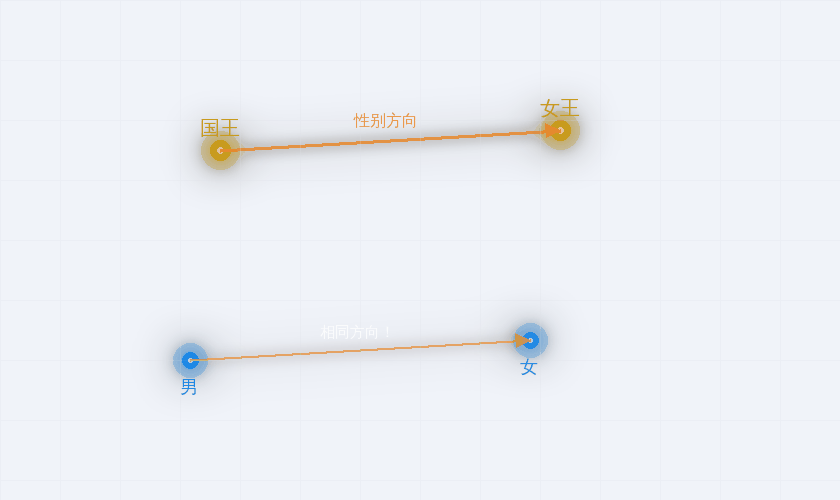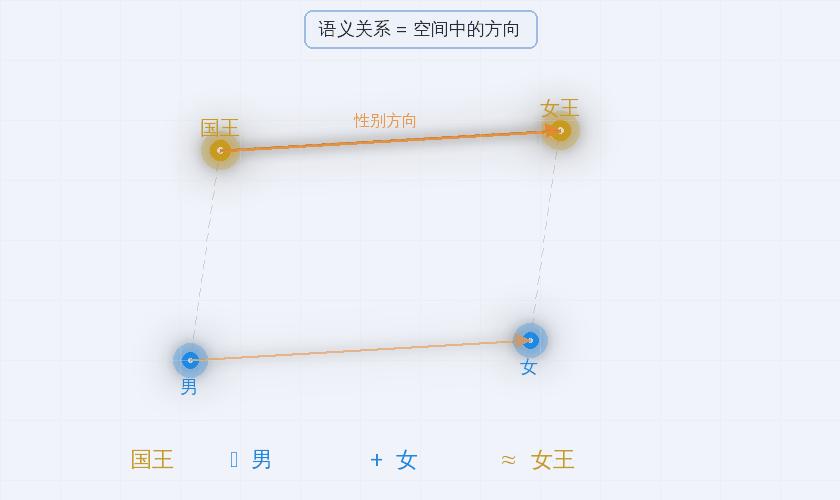
这个发现震惊了整个学术界。它证明了 Firth 说的是对的:你确实可以仅仅通过"同伴关系"来获得有意义的词表示——而且这种意义甚至具有线性几何结构。
但是,这个方法有一个致命的问题。
第四章:一个向量装不下多重含义
白光困境
回到我们的"苹果”。Word2Vec 给每个词一个固定的向量。但:
"苹果好甜" → 苹果 = 水果
"苹果发布会" → 苹果 = 科技公司
"偷吃了禁果" → 苹果 = 文化符号
同一个词,三个完全不同的含义。一个固定的向量怎么装得下?
这就像白光包含了所有颜色。 Word2Vec 的苹果向量是一束白光——所有含义混在一起。你需要一个棱镜,根据上下文把它分解成特定的颜色。
这个困境让人想起 Borges 的短篇小说《巴别图书馆》(1941)——一个包含所有可能书籍的图书馆。每一本书都由随机字母排列而成。其中必然存在解释宇宙奥秘的书、你一生故事的完整记录、以及一切真理。但这些信息无法使用——因为它们淹没在天文数字的噪声中,你没有任何办法找到那本你需要的书。
叠加态的 embedding 就像巴别图书馆——信息存在,但无法直接取用。你需要一个"索引系统"来检索。QKV 就是这个索引。
其实,初始 embedding 并非完全无能——它确实编码了所有这些含义,只是以一种**叠加态(Superposition)**的形式。Anthropic 在 2022 年的研究(Toy Models of Superposition)发现:
神经网络可以在 N 维空间中编码远多于 N 个特征。不常同时激活的特征可以共享维度——就像你可以在同一间教室里安排不同时间的课。
“苹果"的 embedding 之所以能装下"水果"“品牌"“文化"等多重含义,正是因为这些含义在日常使用中很少同时被需要,所以它们可以被近似正交地叠加在同一个向量中。
问题是:叠加态的向量不能直接用。你需要根据上下文,让它"坍缩"到具体的含义。
这个需求——动态的、上下文相关的词义表示——就是 Attention 要解决的核心问题。
第五章:为什么线性变换就够了?
语义空间的几何秘密
在跳到 QKV 之前,我们需要理解一个深刻的事实。回到 Word2Vec 的那个发现:
国王 - 男 + 女 ≈ 女王
这个等式意味着什么?它意味着**“性别"是高维空间中的一条直线(一个方向)**。“王权"是另一个方向。“年龄"又是另一个方向。
这叫做线性表示假说(Linear Representation Hypothesis):
语义特征在高维空间中沿着线性方向排列。
概念之间的关系被编码为向量的加减。
这个假说有一个重大的工程推论:
如果语义特征是线性排列的,那么在这些特征之间做选择、组合、重新对齐的最自然工具是什么?
线性变换——也就是矩阵乘法。
一个矩阵 W × x 在几何上做三件事:
语义空间中的关系是线性的,而矩阵正是线性变换的工具——QKV 的线性投影之所以有效,恰恰是因为语义结构本身就是线性的。
但线性投影只是数学工具。要理解 QKV 为什么长这个样子,我们还需要理解另一层约束——机器的世界长什么样。
第六章:机器世界的设计约束——为什么是 Attention
一切皆数字
在人的世界里,理解语言可以依赖眼睛看到的颜色、舌头尝到的味道、皮肤感受到的温度。但机器没有这些。
对机器来说,世界上的一切——文字、图像、声音——都是数字序列。
一段文字是一串 token ID。一张图片是一个像素矩阵。一段语音是一列振幅采样值。机器要处理"苹果好甜”,看到的不过是 [8943, 1762, 4521] 这样的数字。
这意味着,机器处理语言的方案必须能在纯数字的世界里运行。这施加了一组严格的设计约束:
约束一:可并行
2017 年之前,处理序列的主流工具是 RNN(循环神经网络)——它必须从左到右逐词处理,前一个词处理完才能处理下一个。
但 GPU 的本质是并行计算。如果模型必须一步一步走,GPU 的几千个核心大部分时间都在闲着。
Attention 的关键创新:每个词可以同时和所有其他词计算关系。 这使得 GPU 可以全速运转——这也是 Attention Is All You Need 的真正含义:不再需要 RNN 的顺序处理。
约束二:可微分
机器学习的核心是梯度下降——通过反向传播计算误差,然后微调参数。这要求整个计算流程必须是可微分的。
早期也有研究者尝试过"硬注意力(Hard Attention)"——直接选择最相关的那一个词。但"选择"是离散操作,无法求梯度。
Softmax 是关键:它把离散的"选择"变成连续的"加权”。 不是"选不选”,而是"多关注还是少关注”。这使得梯度可以端到端地流动,让模型通过训练自动学会该关注什么。
约束三:自注意力 = 内容可寻址
传统计算机的内存是按地址寻址的:你知道数据在第几行第几列,你就能找到它。但语言中的关联不是按位置的——“苹果"需要根据内容找到和它相关的词。
自注意力实质上是一种内容可寻址的记忆系统。 Q 是查询内容,K 是存储标签,V 是存储的值——这与 Graves 等人(2014)提出的**神经图灵机(Neural Turing Machine)**的读取头如出一辙。
约束四:位置需要显式注入
RNN 天然知道词的顺序(因为它逐步处理)。但 Attention 对所有词一视同仁——如果不加干预,“狗咬人"和"人咬狗"对 Attention 来说完全一样。
因此 Transformer 需要位置编码(Positional Encoding)——用正弦函数或可学习的向量,把"第几个词"这个信息显式地加入到 embedding 中。
这些约束决定了 QKV 的形态
回顾这四个约束:
要处理纯数字序列 → 需要向量运算
要并行计算 → 不能逐步处理,需要全局交互
要可微分 → softmax 取代硬选择
要按内容寻址 → Q 查询、K 匹配、V 返回
要知道顺序 → 位置编码
但这里需要停下来,强调一件容易被忽略的事:
这些约束告诉我们 QKV 的形状,但没有告诉我们 QKV 的内容。
W_Q、W_K、W_V 三个矩阵在模型初始化时是随机噪声。它们不包含任何语言知识——没有人在里面编码"甜和水果有关"或"发布会和科技公司有关”。
人类设计者提供的不是答案,而是一个允许答案涌现的空结构。
这才是 Transformer 与规则路线最深层的分野:
规则路线: 人类编码知识 → 机器执行
Transformer: 人类编码学习的框架 → 数据教会机器 → 知识从框架中涌现
QKV 就像 DNA——DNA 不编码"如何走路”,它编码"如何长出一个能学会走路的身体”。W_Q、W_K、W_V 不编码任何语义关系,它们编码的是"如何从数据中学会语义关系"的能力。
那么,是什么赋予了这些空矩阵以灵魂?
不可或缺的三要素
语料——人类文明的压缩
GPT-3 训练用了约 3000 亿个 token——大致相当于整个互联网的文本、几万本书、数百万篇论文。这些文本不只是"数据”,它是人类几千年来用语言记录下的一切思考、对话、争论、叙述和知识。
没有这些语料,QKV 的矩阵就只是随机噪声,永远无法学会任何语义关系。语料是 Transformer 的"经验”,是它的"一生"。
算力——让涌现成为可能
梯度下降需要在几十亿参数的空间中寻找最优点。GPT-3 的训练消耗了约 3640 PetaFLOP-days 的算力——相当于一台普通笔记本电脑运算约一千万年。
没有这样的算力,即使有完美的框架和无限的数据,模型也无法完成学习。算力是涌现的催化剂。
自由度——不预设答案
这也许是最深刻的一点。Transformer 的设计者刻意不在模型中硬编码任何语言规则。没有语法树,没有词性标注,没有语义角色。所有的参数都是可学习的——模型拥有极高的自由度来自行发现结构。
这种"空白"不是缺陷,而是设计哲学。正是因为不预设答案,模型才能找到人类可能想不到的模式——比如在高维空间中自动形成线性语义方向。
框架(QKV 结构)× 语料(人类文明)× 算力(计算规模)× 自由度(不预设答案)
四者缺一不可。缺少任何一个,都不会有 ChatGPT。
第七章:QKV 的运作——从点积到含义重建
空框架如何被数据填充
我们已经知道,QKV 的矩阵在初始化时什么都不知道。那么,训练之后它们学会了什么?让我们回到那个句子:
“苹果好甜”
当你读到"苹果"时,你的大脑做了什么?
1. 你看到"苹果" → 心里产生一个问题:"这里的苹果是什么意思?"
2. 你扫描上下文 → 看到"甜","甜"举手说:"我和水果义很相关!"
3. 你从"甜"那里获取信息 → 确认这是水果苹果,而且在说口感
有趣的是,训练后的 Transformer 做的事情几乎一模一样。没有人教它这三步——它从海量文本中自己发现了这个模式。Q、K、V 三个角色,是从数据中涌现出来的:
"苹果"发出的问题:我在这个句子里该是什么意思?
每个上下文词亮出的名牌:我能提供什么类型的信息?
名牌匹配后,实际递出的信息:我的具体语义内容。
为什么需要三个矩阵,而不是一个?
这是 QKV 设计中最关键的洞察:
同一个词在不同角色下需要呈现不同的侧面。
- 当"甜"被别人搜索时(作为 Key),它应该突出"我与食物/味觉相关"
- 当"甜"提供信息时(作为 Value),它应该提供"正面口感、糖分"等具体语义
- 当"甜"自己提问时(作为 Query),它可能在问"谁是我描述的对象?"
同一个词,三个角色,三个不同的投影——就像一束白光穿过三面棱镜,折射出不同颜色的光。

棱镜本身是透明的——W_Q、W_K、W_V 初始时什么都不知道。是海量文本中的统计规律,通过梯度下降,一点一点打磨了这三面棱镜的角度,使得同一束白光能在合适的方向上折射出合适的颜色。
完整的计算流程
让我们完整地走一遍"苹果好甜"中"苹果"获取上下文含义的过程:
第一步:生成 Q、K、V
每个词的 embedding 分别乘以三个矩阵 W_Q、W_K、W_V,得到三组向量:
苹果 → Q_苹果, K_苹果, V_苹果
好 → Q_好, K_好, V_好
甜 → Q_甜, K_甜, V_甜
第二步:Q·K 点积 = 相似度
“苹果"的 Q 向量与所有词的 K 向量做点积,得到"注意力分数”:
Q_苹果 · K_苹果 = 0.2 (和自己的相关度)
Q_苹果 · K_好 = 0.1 ("好"是修饰词,相关度低)
Q_苹果 · K_甜 = 0.8 ("甜"直接说明苹果的属性,高度相关)
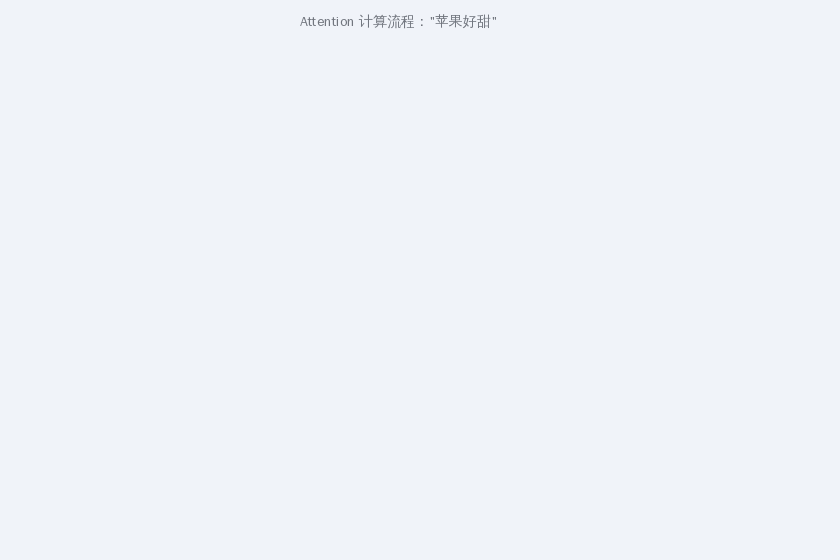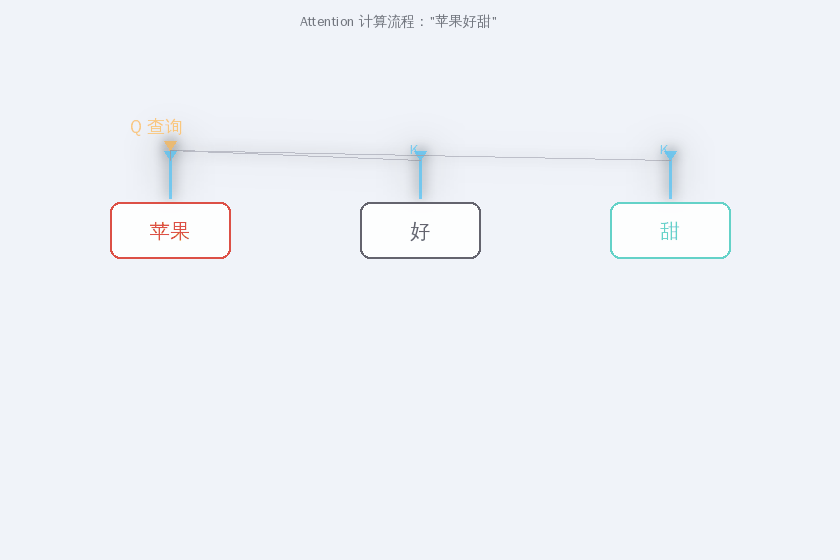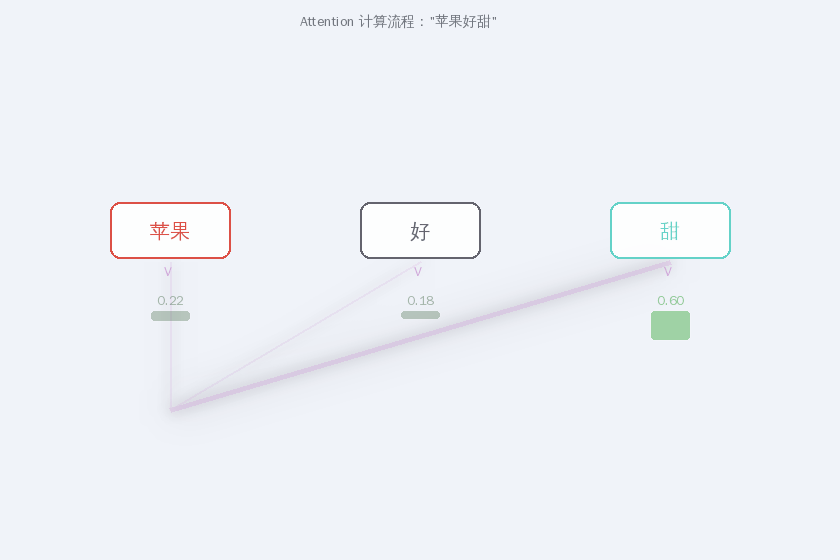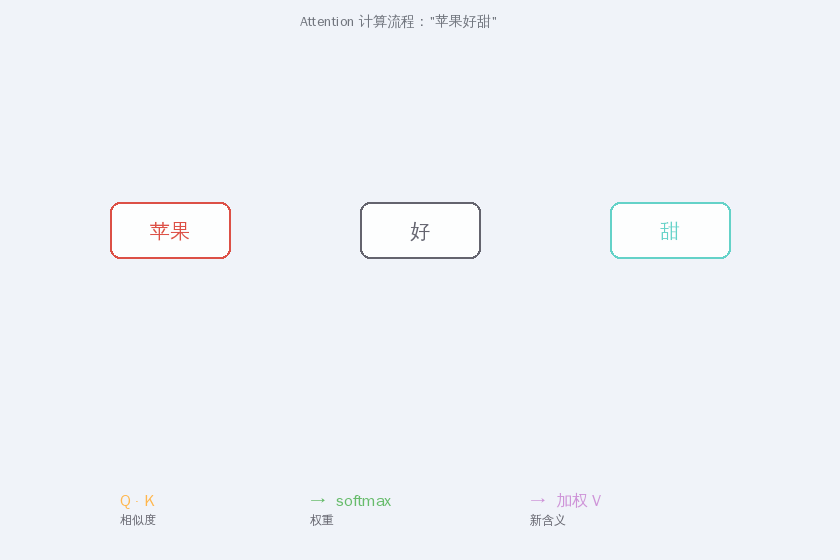
第三步:Softmax = 权重
原始分数通过 softmax 归一化为概率分布:
softmax([0.2, 0.1, 0.8]) → [0.22, 0.18, 0.60]
“甜"获得 60% 的注意力权重——这就是 Attention 的"注意力”。
第四步:加权聚合 V = 新含义
按权重混合所有词的 V 向量:
苹果' = 0.22 × V_苹果 + 0.18 × V_好 + 0.60 × V_甜
这个新的向量 苹果' 不再是那个模糊的叠加态——它被"甜"主导,已经坍缩到了水果的含义。
三个矩阵 W_Q、W_K、W_V 做的事情就是:把同一个高维 embedding 旋转、投影到三个不同的子空间,让每个词在每个角色下都有最合适的表示。
请注意这里最不可思议的地方:没有任何一行代码告诉模型"甜和水果有关"。 模型只是在训练中见过无数次"苹果"和"甜"在同一个句子里出现,见过无数次"苹果"和"发布会"在另一类句子里出现。梯度下降自动调整了 W_Q、W_K、W_V 的参数,使得"甜"的 K 向量恰好和"苹果在水果语境中"的 Q 向量对齐。
这些语义关系不是被编程进去的,是从人类几千年的语言使用中被"蒸馏"出来的。
信息检索的类比
QKV 的命名直接来自数据库/信息检索的概念:
你在搜索引擎输入 Query → "苹果是什么水果?"
数据库每条记录有 Key → "苹果:水果类,蔷薇科"
匹配后返回 Value → "苹果,落叶乔木,果实球形……"
Transformer 的创新是:让这个"搜索"过程可微分、可学习。 Q、K、V 不是人工定义的索引和记录,而是模型在海量文本中自己学出来的。
第八章:高维空间中的语义坍缩
从叠加态到确定态
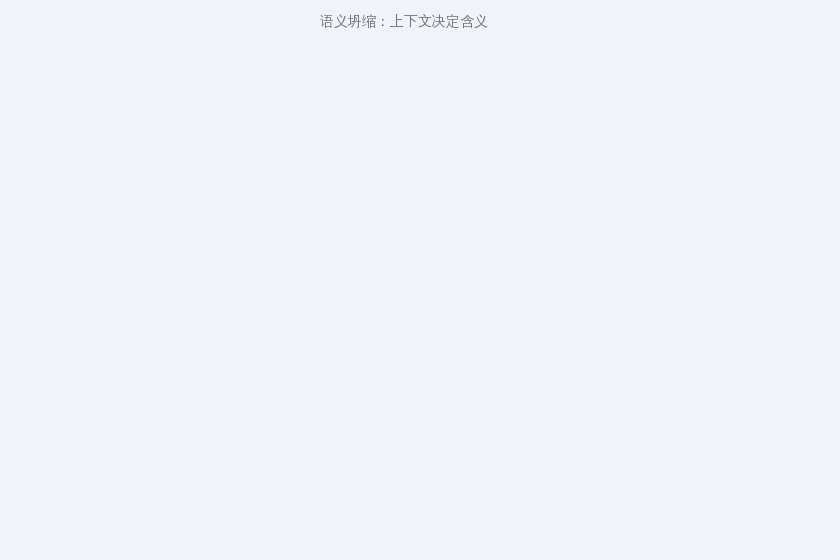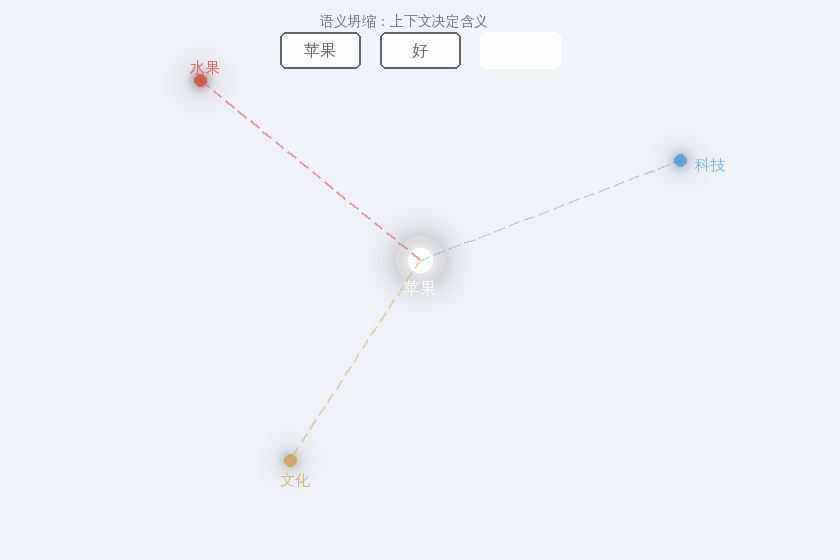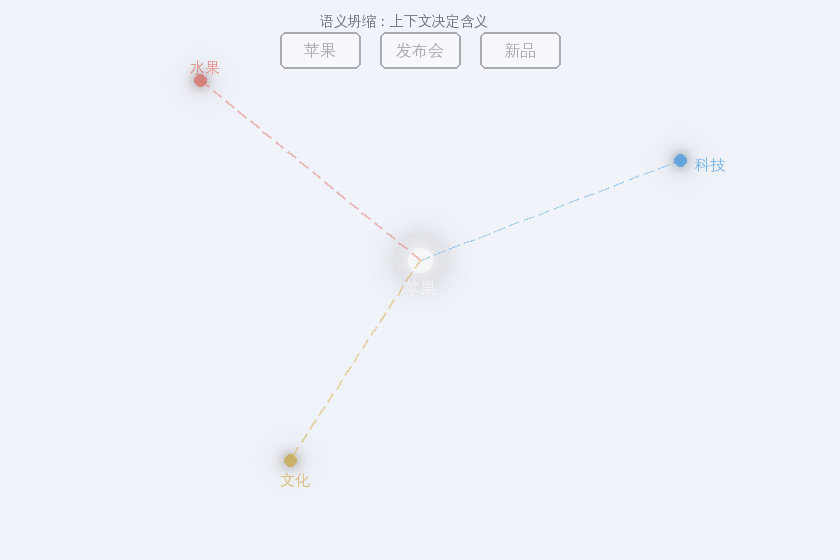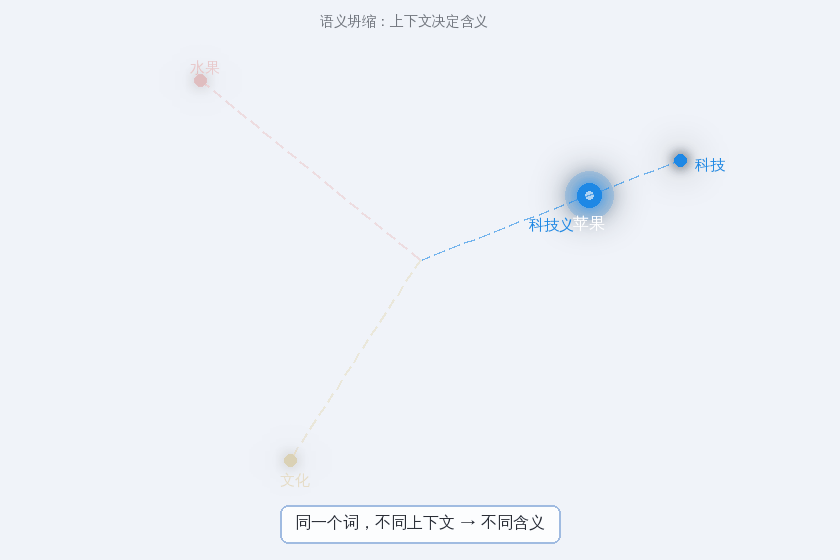
现在我们可以完整地描述这个过程:
Attention 之前: “苹果"的 embedding 是叠加态——水果、品牌、文化符号等所有含义压缩在一个向量中
Attention 之后: 通过 QKV 与上下文的交互,“苹果"的向量被重写——它从叠加态"坍缩"到了特定上下文对应的含义
“苹果好甜” → 向量向"水果"方向移动
“苹果发布会” → 向量向"科技公司"方向移动
多头注意力:同时关注多种关系
一组 QKV 只能关注一种类型的关系。但语言中的关系是多维的:
"小明昨天在学校吃了一个苹果"
需要同时关注:
- 语法关系:谁吃了什么?(小明 → 吃 → 苹果)
- 时间关系:什么时候?(昨天)
- 地点关系:在哪里?(学校)
- 语义消歧:哪个苹果?(甜 → 水果义)
这就是**多头注意力(Multi-Head Attention)**的设计动机——多个平行的 QKV 组,每个头学习关注不同类型的关系。
Transformer 的每一层不是"处理后传给下一层”,而是:
x → x + Attention(x) → x + Attention(x) + FFN(x) → ...
这个 + 是关键。向量 x 是一条信息总线:每个 Attention 头读取总线上的某些信息,写回新的信息。不同的头关注不同的维度,最终的向量是所有层所有头的贡献之和。
第九章:趋同演化——当硅基重新发现碳基的方案
婴儿也是统计学习者
我们已经看到,机器通过统计共现来学习语言。但令人惊讶的是——人类婴儿可能也在做类似的事情。
1996 年,心理学家 Jenny Saffran 做了一个优美的实验:她给 8 个月大的婴儿播放一串连续的无意义音节流(如 “bidakupado…"),其中某些音节组合出现的频率更高。
结果令人震惊:仅仅 2 分钟后,婴儿就能区分高频组合和低频组合。 他们在没有任何语法规则、没有任何明确教导的情况下,纯粹通过统计规律发现了"词"的边界。
这和 Word2Vec 的核心思想惊人地一致——通过共现频率来学习结构。
预测机器
更深层的联系来自神经科学。Karl Friston 的自由能原理和 Andy Clark 的**“预测大脑"理论**提出:
大脑的核心功能不是"反应”,而是"预测”。
大脑不断预测下一个感觉输入会是什么,然后用实际输入和预测的差异(预测误差)来更新自己的模型。
这和 GPT 的训练目标一模一样——预测下一个 token,然后用预测误差(loss)来更新权重。
| 维度 | 人脑 | LLM |
|---|---|---|
| 核心任务 | 预测下一个感觉输入 | 预测下一个 token |
| 学习信号 | 预测误差(surprise) | 交叉熵损失(loss) |
| 表示方式 | 分布式神经元激活 | 分布式向量表示 |
| 结构 | 层级化(V1→V2→V4→IT) | 层级化(Layer 1→2→…→N) |
| 上下文整合 | 注意力选择 + 工作记忆 | Self-Attention |
实验证据
这不仅仅是类比。Schrimpf 等人(2021)发现,GPT-2 的中间层表示竟然能预测人脑语言区域的 fMRI 激活模式——越好的语言模型,预测人脑活动的能力也越强。
Goldstein 等人(2022)更进一步:他们发现当人类听故事时,大脑语言区域的神经活动与 GPT-2 逐词预测时的内部表示高度相关。
趋同演化假说
在生物学中,有一个现象叫趋同演化(Convergent Evolution)——眼睛在动物进化中独立出现了几十次,因为"看见"这个功能对生存太重要了。不同的基底(章鱼的眼睛和人的眼睛结构完全不同),因为面对同一个问题(需要感知光线),收敛到了类似的方案。
语言处理可能也是如此:
不同的基底(生物神经元 vs 矩阵运算),因为处理同一个任务(预测序列中的下一个元素),可能收敛到了类似的内部表示。
当然,关键差异依然存在:
- 数据效率:儿童用大约 1000 万词就能流利说话,GPT-3 训练用了 3000 亿词——差了 3 万倍
- 具身性:人通过身体与世界互动来接地语义,LLM 只有文本
- 社会学习:人在对话和互动中学习,LLM 从静态语料中学习
但这些差异恰恰让趋同更有意义——即使学习方式如此不同,最终的内部表示却如此相似,说明这种表示方式可能是处理序列预测问题的某种"最优解”。
一个更深的问题: 为什么"预测下一个"这么简单的目标,会产生如此丰富的内部表示?也许是因为,要真正预测好下一个词,你必须理解因果、时间、意图、常识——你必须建立一个世界模型。 预测不是智能的副产品,预测本身可能就是智能的核心机制。
结语:回到那个死循环
让我们回到最初的问题:语言是什么?
我们走过了一条漫长的路:
语言是对世界的压缩
↓
但符号不能自我解释 — 符号接地问题 (Harnad, 1990)
↓
人类第一次尝试:用规则教机器 — 40 年,失败
↓
破局:意义 = 上下文共现 — 分布式假说 (Firth, 1957)
↓
第一次实现:Word2Vec — 一个词一个固定向量
↓
问题:"苹果"有多重含义,一个向量不够
↓
机器的约束:纯数字 + 可并行 + 可微分 + 内容可寻址
↓
人类设计了一个空框架:QKV 结构 — 不编码知识,编码学习的能力
↓
语料(人类文明)× 算力(计算规模)× 自由度(不预设答案)
↓
知识从框架中涌现 → Attention 学会了上下文驱动的含义重建
↓
惊人发现:这个方案与人脑的语言处理高度趋同
一个词的 embedding 就像白光——它包含所有颜色。QKV 的三个矩阵就像三个棱镜,把白光分解成不同的光谱。但这些棱镜不是人工打磨的——它们是从数十亿句人类语言中,被梯度下降自动雕刻出来的。人类提供了玻璃坯料和打磨工具,但棱镜的形状是数据决定的。
最后三个问题留给读者:
语言是什么? → 也许不是规则,而是统计结构——意义从共现中涌现。Wittgenstein 晚年认为,语言没有固定本质,只有无数交织的"使用模式"。Transformer 用数学实现了这个哲学直觉。
理解是什么? → 也许只是高维空间中的模式匹配——能够在正确的上下文中,将叠加态坍缩到正确的含义。OpenAI 联合创始人 Ilya Sutskever 说过:“Compression is understanding."——如果一个系统能用更少的 bits 描述同样的文本,它就在某种意义上"理解"了那些文本。LLM 所做的,本质上就是对人类语言的极致压缩。
人和机器的关系? → 不同的道路,类似的终点——趋同演化的又一个实例。也许"智能"不是某种特定基底的专利,而是任何足够复杂的系统在面对序列预测任务时,都会涌现出的几何结构。
Bender & Koller (2020) 在论文 “Climbing towards NLU” 中提出:LLM 只是在操纵语言的"形式”(form),没有接触到真正的"意义"(meaning)——它们是"随机鹦鹉"(stochastic parrots)。但反对者问:如果一个系统在功能上与"理解"无法区分,那"真正的理解"这个概念本身是否还有意义? 这是功能主义与本质主义之间古老的哲学争论,在 AI 时代重新燃起。
也许答案是——这本身就不是一个有答案的问题,而是一面镜子。 我们在追问"机器是否理解语言"的过程中,被迫重新思考自己是如何理解语言的。而正是这种思考本身,构成了意义。
参考文献
- Harnad, S. (1990). The Symbol Grounding Problem. Physica D, 42, 335-346.
- Firth, J.R. (1957). A Synopsis of Linguistic Theory 1930-1955. — “You shall know a word by the company it keeps”
- Chomsky, N. (1957). Syntactic Structures. Mouton. — 形式文法
- Winograd, T. (1971). Procedures as a Representation for Data in a Computer Program for Understanding Natural Language. MIT. — SHRDLU
- Fillmore, C.J. (1968). The Case for Case. — 格语法
- Mikolov, T. et al. (2013). Efficient Estimation of Word Representations in Vector Space. — Word2Vec
- Mikolov, T. et al. (2013). Linguistic Regularities in Continuous Space Word Representations. — king-queen 线性关系
- Vaswani, A. et al. (2017). Attention Is All You Need. NeurIPS. — Transformer / QKV
- Bahdanau, D. et al. (2015). Neural Machine Translation by Jointly Learning to Align and Translate. — Attention 机制前身
- Graves, A. et al. (2014). Neural Turing Machines. — 神经图灵机 / 内容可寻址记忆
- Elhage, N. et al. (2022). Toy Models of Superposition. Anthropic. — 叠加假说
- Elhage, N. et al. (2021). A Mathematical Framework for Transformer Circuits. Anthropic. — Residual stream 理论
- Park, K. et al. (2023). The Linear Representation Hypothesis and the Geometry of Large Language Models. — 线性表示假说
- Saffran, J.R. et al. (1996). Statistical Learning by 8-Month-Old Infants. Science. — 婴儿统计学习
- Friston, K. (2010). The Free-Energy Principle: A Unified Brain Theory? Nature Reviews Neuroscience. — 自由能原理
- Clark, A. (2013). Whatever Next? Predictive Brains, Situated Agents, and the Future of Cognitive Science. — 预测大脑
- Schrimpf, M. et al. (2021). The Neural Architecture of Language: Integrative Modeling Converges on Predictive Processing. PNAS. — LLM 预测人脑活动
- Goldstein, A. et al. (2022). Shared Computational Principles for Language Processing in Humans and Deep Language Models. Nature Neuroscience. — GPT-2 与人脑相关性
- Jelinek, F. (1988). 引述于 The Handbook of Computational Linguistics. — “每开除一个语言学家”
- Wittgenstein, L. (1953). Philosophical Investigations. — “一个词的意义就是它在语言中的使用” (§43)
- Borges, J.L. (1941). The Library of Babel. — 巴别图书馆:包含一切可能书籍的图书馆
- Bender, E.M. & Koller, A. (2020). Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data. ACL. — “随机鹦鹉"之争
本文首发于「AI 学习笔记」博客:https://Jason-Azure.github.io/ai-blog/
微信公众号:AI-lab学习笔记
延伸阅读:Attention 机制零基础拆解 · 矩阵——空间的变形术
